Pangeo Forge为气象海洋的云计算和大数据而生,是一种众包(crowd sourcing)科学数据制作方法,目前Pangeo社区负责该技术的开发。
云计算
云计算为科学研究提供了极大便利,使我们可以将算力部署在数据服务器周围,这些服务器往往由Google或者AMS等大厂维护,先进的硬件设施和强大算力使得数据读取速度大大提高,这避免了将数据下载到计算机进行处理。
数据格式
大气海洋领域、测绘、遥感等领域大量使用的Netcdf格式不适合大数据的云计算,为了适用于大数据和云计算,一种新的多维数据结构Zarr应运而生,成为Pangeo气象海洋云数据的规范格式。
规范化的数据是高效云计算的前提。就像Python有无数的大众开发的软件包,可以通过pip等安装,但最稳定可靠的安装是使用Conda Forge,这是一个更规范化的Python源。Pangeo Forge的出现即受其启发,主要目的是维护一个规范化的云数据源。
技术流程
Pangeo Forge的技术细节并不复杂,简单说它利用了GitHub的pull request功能,任何人可以Fork在GitHub上的Pangeo Forge仓库,对meta.yaml和recipe.py两个文件修改,设置数据的源等信息,然后pull request,这样就会在这个仓库深成一个数据制作的申请,机器人会检核申请,若无误则进入数据制作步骤。一旦制作完成,数据即在云端公开可见。
Pangeo Forge不需要用户自己下载上传数据,只要提供数据的源地址,系统将自动爬取数据,进行数据格式的转换,最终存储在Pangeo的云端(Google Cloud服务商)。
全球任何人均可以使用Pangeo Forge制作规范化云数据,并存储在Pangeo的Google云端。这其中的数据下载上传、格式转化所耗费的流量和算力,以及数据所占的云存储将产生不小的费用,均已由Pangeo所获得的基金资助支付,目前对所有人免费开放使用。
初期阶段
Pangeo Forge仍旧在初期阶段,目前完成制作的标准数据并不多,例如现在发布的数据有:
大量的申请得到许可后,进入处理列队,这一过程可能比较缓慢。目前列队中有1000多个任务正在等待处理。
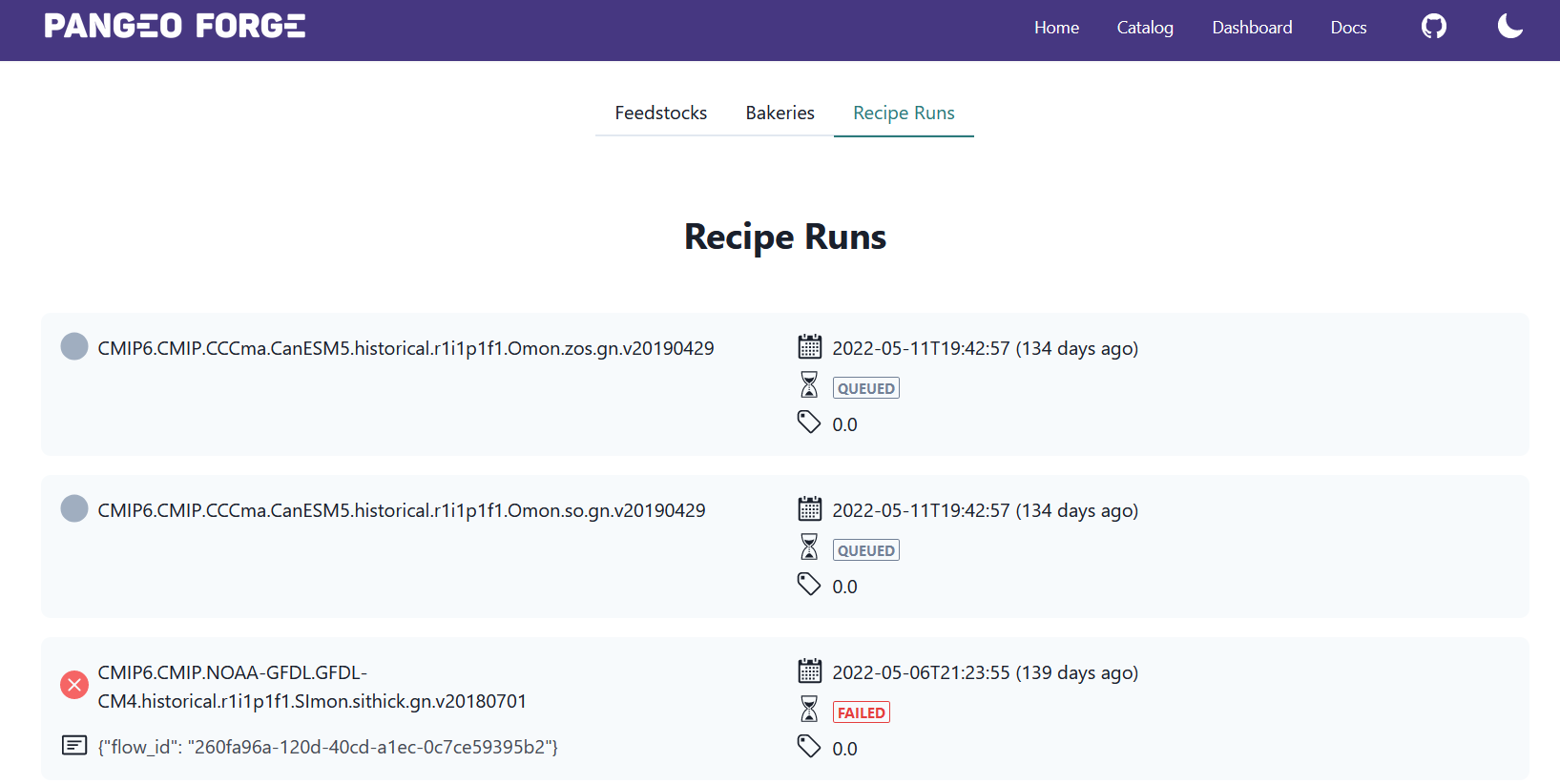
Pangeo Forge实例
这里放一个Pangeo Forge的视频,视频后半段有实例讲解,演讲者即Pangeo创始人Ryan Abernathey:
尝试云数据
云计算的高效到底多震撼呢?
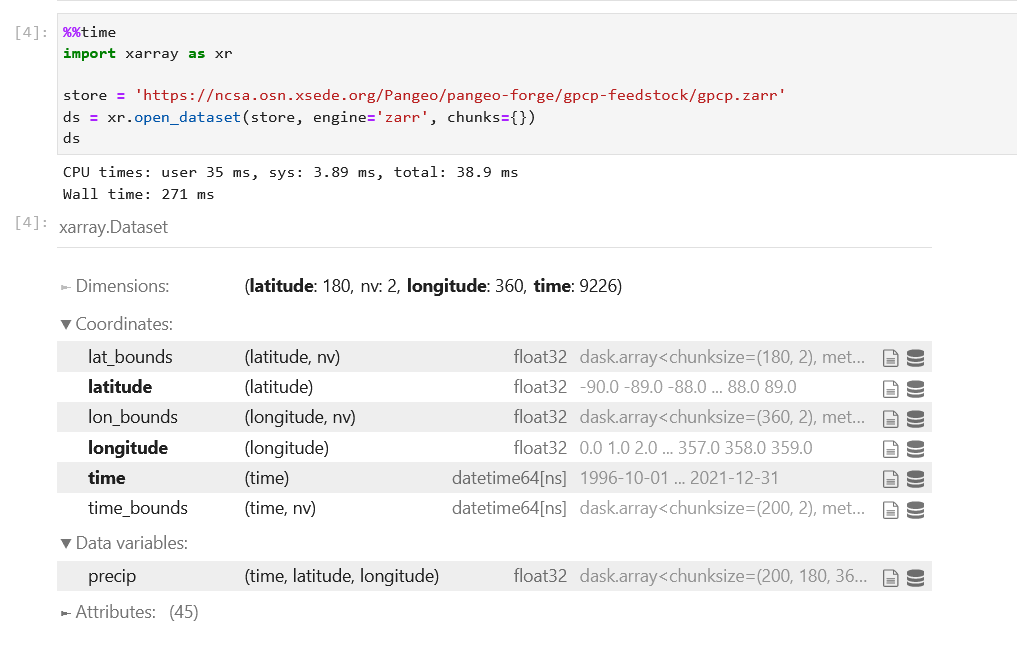
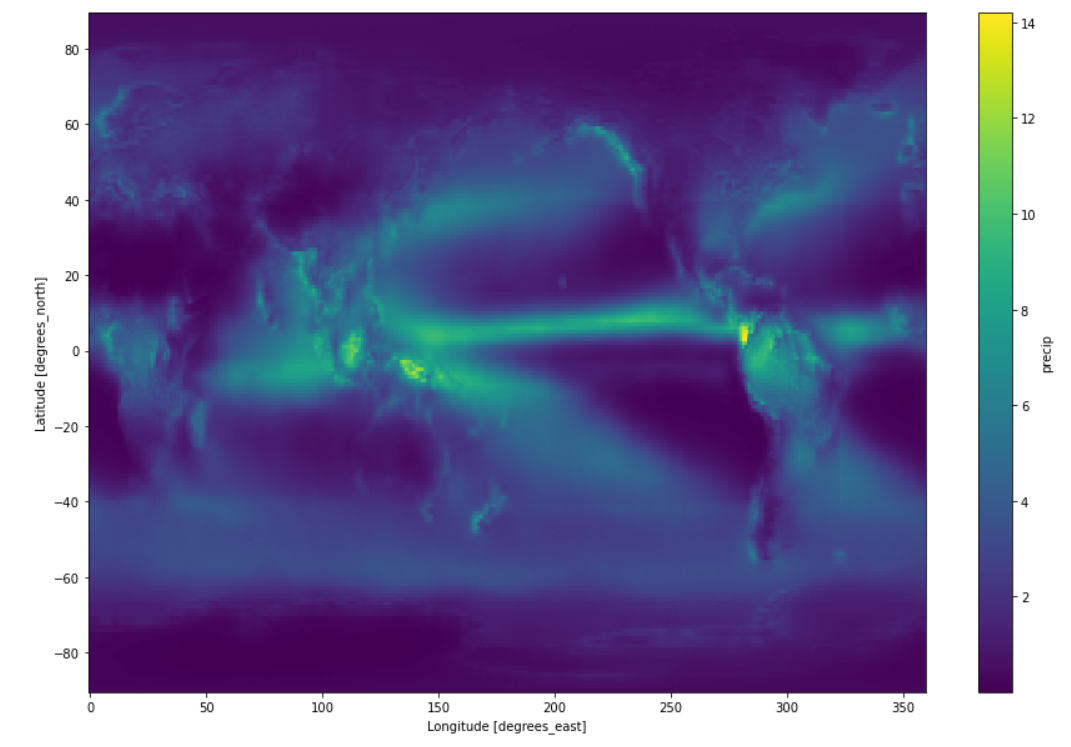
我们可以瞬间打开九千个NOAA的降水文件,几秒钟完成九千个文件的气候态计算,并绘图展示。
以上面视频所提到的降水为例:
1 | %%time |
计算降水气候态:
1 | from dask.diagnostics import ProgressBar |
小结
- Pangeo Forge目的是为了制作规范化的Zarr格式数据
- 所有步骤均在云上进行,包括数据抓取,格式转换和数据部署
- 处在项目初期,列队内容多,排队等待时间长
- 尚不能及时的自动更新数据
Pangeo 云计算的生态系统非常值得尝试,已经较成熟,Pangeo Forge还不是很成熟,想法超前,不建议新人制作维护自己的数据。
下节预告
- Pangeo Forge 制作FIO-COM32(海洋一所)海洋模式数据
- 云上处理FIO模式,计算混合层厚度。