Citespace 分析研究趋势和热点
citespace安装和使用
百度、知乎
web of science
需要账号。
可以从淘宝购买:https://item.taobao.com/item.htm?_u=ears19s341b&id=626203048883
wos导出文献
选择纯文本格式,全纪录和引文
运行citespace
直接放到data中,go.
结果
这里以最近我的一个研究点为例子,通过上述步骤,运行citespace得到:



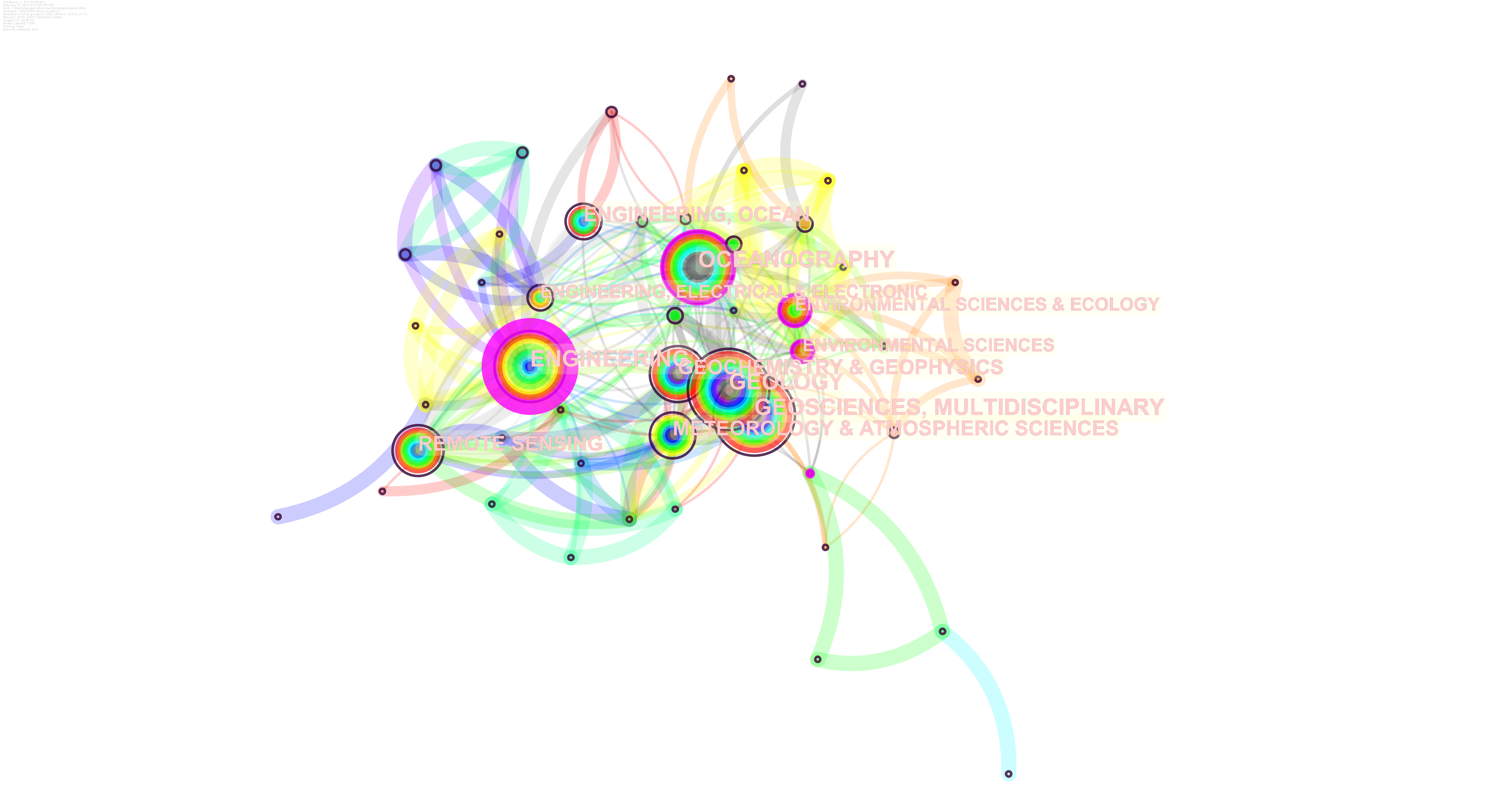
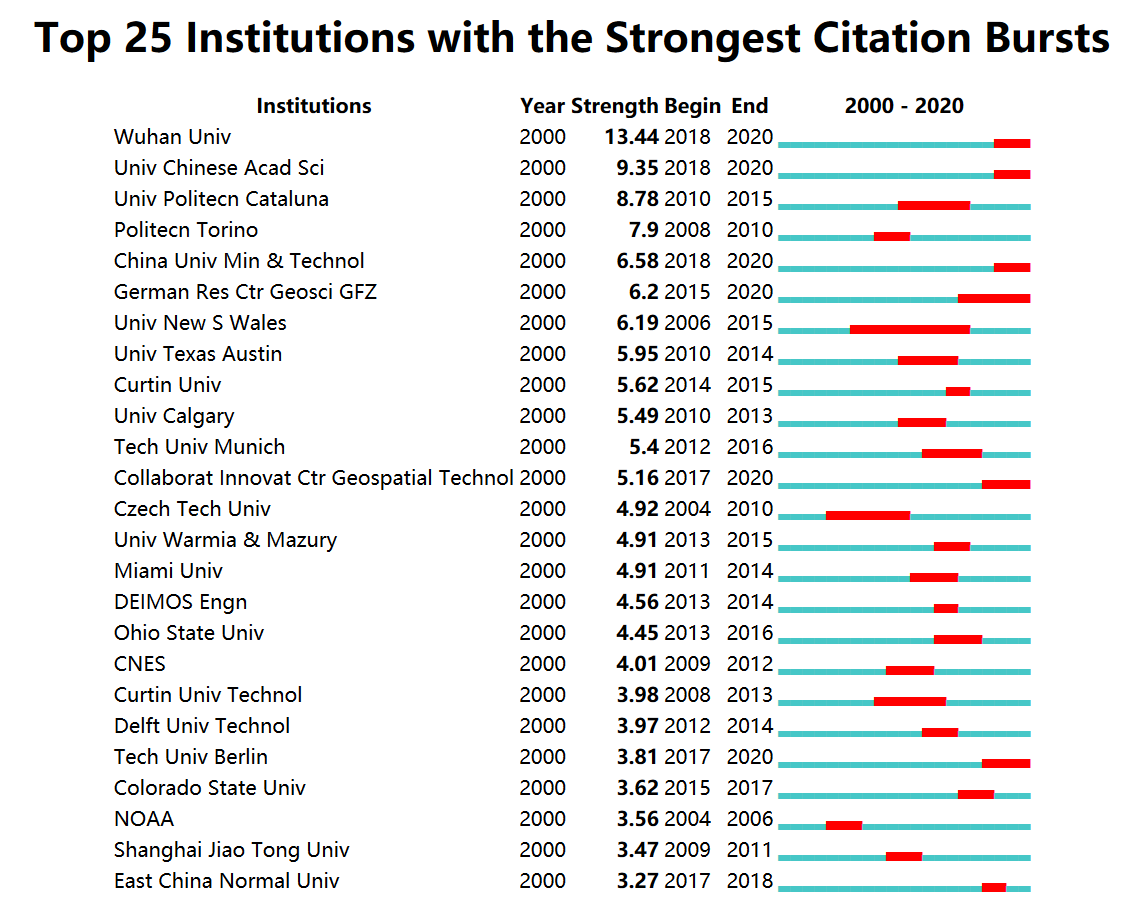
burst
- 选择想要分析的参数,如keyword,country或者institution等
- go
- 点击citation/Frequency burst
- visualization-citation/Frequency burst history
CNKI
CNKI的信息完整性很差,无法实现共引分析、合作分析等。以GNSS浮标的研究文献为例:
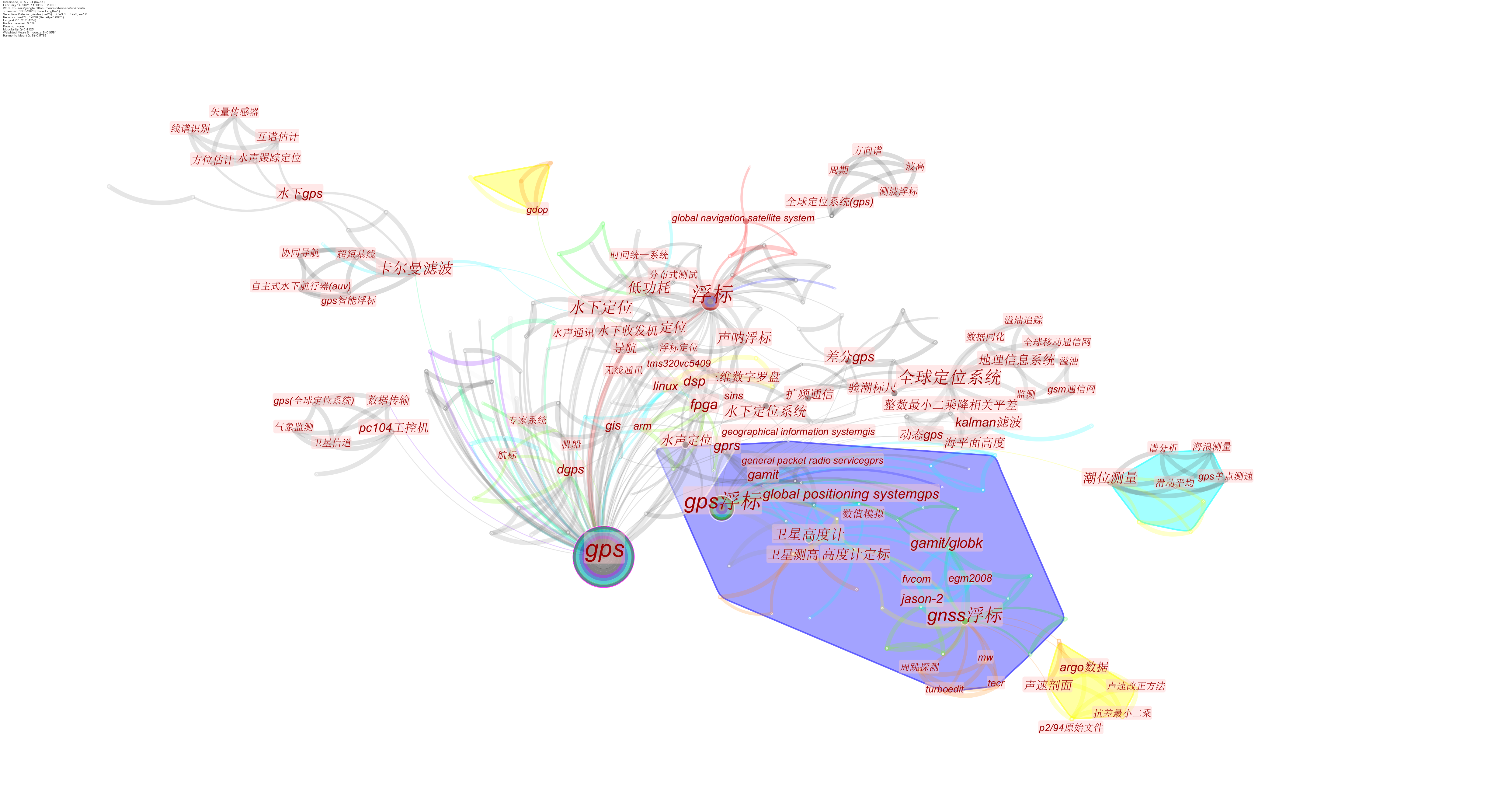



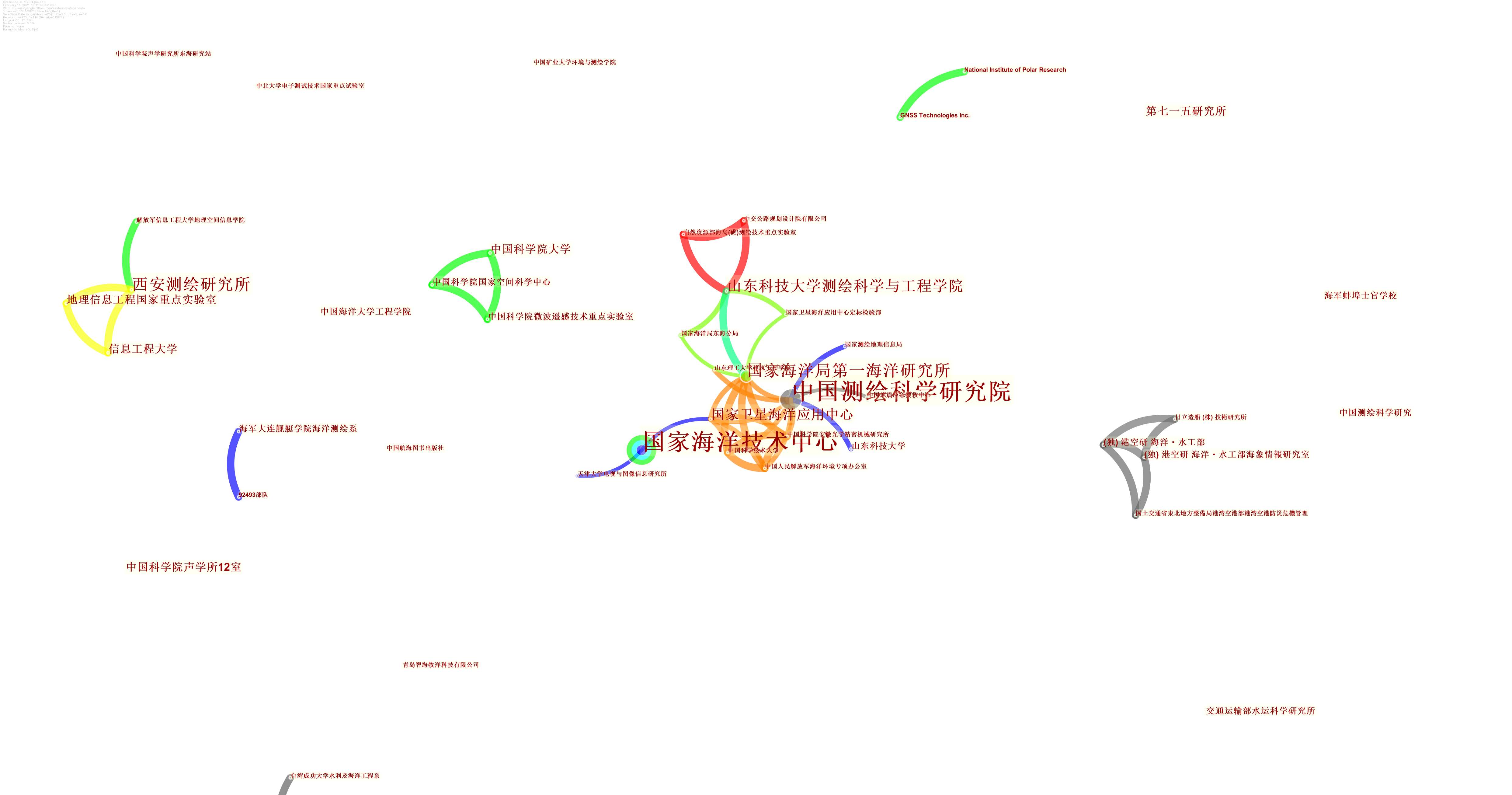
国内这方面的合作不密切,各自为核心。
问题
标签重复
1
2
3
4
5
6
7
8
9
10
11
12
13聚类时候常常出现同一个意思不同的表达,或者同一个作者不同的写法(尤其英文)
这个时候就需要合并同义词
有两种方法:
方法一:在视图模式下,右键关键词节点,add to alias list(primary),右键另一个关键词,add to alias list(secondary),这样关掉窗口,重新GO,就可以发现第二个关键词被第一个关键词合并了。但这个时候关键词肯能不容易选中,尤其其节点比较小的时候。于是有了第二种方法
方法二:右键关键词节点的不好选中,或者当需要合并的关键词过多时,在project文件夹里新建一个txt文件,命名为citespace.alias,内容格式如:@PHRASEXXX#@PHRASE***,这样第二个词就被合并到第一个词里面去了。(如果你已经按方法1进行了操作,这个文件就自动生成了,你之要用记事本打开进行操作就可以了)
要注意的是:第二种方法英文一般不会出问题,但中文的时候会出现不起作用的情况(而且citespace.alias文件里的关键词是乱码),这时候你需要把该文件另存为utf-8编码格式就OK了。
(https://zhuanlan.zhihu.com/p/81028371)例如:
1
2
3@PHRASEgnss buoy#@PHRASEgps buoy
Chinese Acad Sci#Chinese Acad Sciences
@PHRASEGPS#@PHRASEgp聚类重复
在cluster-extract cluster labels那里选择cast by top n%=100
use keyword聚类较多
clusters>show clusters by IDs,之后在出来的对话框里填写你想要保留的标签序号,用英文状态下的逗号隔开即可。
那么这里面能得到什么信息呢?很多信息。
- 研究机构分布
- 国家分布
- 作者合作关系
- 共同引用文献
- 等等
当然里面的信息不能直接转化为所需要的价值,还需要自己分析一下。
注:
比较遗憾的是Google Earth Kml的功能现在不能使用。
CNKI如果出现时间错误信息,可以点击Tern type–>Noun Phrases,然后选择Tern,即可分析。不做次操作可能有时间段内找不到数据的提示,无法工作。原因不详。
CNKI遗憾的是,由于信息不完备,不能做太多的分析,如引文分析、引文作者、引文期刊等。
注意:A引用了B文献,那么A为施引文献,B为被引文献。如果在node types选择Author则分析施引文献,就是下载到的数据条目的作者分析,如果选择cited author,就是从下载到的条目数据的引文中进行分析,看这些文献引用了哪些作者的文章。
简单理解就是:对施引文献聚类分析,更能够得到当下的研究热点以及趋势。